A Large-Scale Corpus for Conversation Disentanglement (Kummerfeld et al., 2019)
This post is about my own paper to appear at ACL later this month. What is interesting about this paper will depend on your research interests, so that’s how I’ve broken down this blog post.
A few key points first:
- Data and code are available on Github.
- The paper is also available.
- The general-purpose span labeling and linking annotation tool we used is also appearing at ACL.
- Check out DSTC 8 Track 2, which is based on this work.
You study discourse
We investigated discourse structure when multiple conversations are occurring in the same stream of communication. In our case, the stream is a technical support channel for Ubuntu on Internet Relay Chat (IRC). We annotated each message with which message(s) it was a response to. As far as we are aware, this is the first large-scale corpus with this kind of discourse structure in synchronous chat. Here is an example from the data, with annotations marked by edges and colours:

We don’t frame the paper as being about reply-structure though. Instead, we focus on a byproduct of these annotations - conversation disentanglement. Given our graph of reply-structure, each connected component is a single conversation (as shown by each colour in the example). The key prior work on the disentanglement problem is Elsner and Charniak (2008), who released the largest annotated resource for the task, with 2,500 messages manually separated into conversations. We annotated their data with our annotation scheme and 75,000 additional messages.
We built a set of simple models for predicting reply-structure and did some analysis of assumptions about discourse from prior disentanglement work, but there is certainly more scope for study here. One direction would be to develop better models for this task. Another would be to study patterns in the data to understand how people are able to follow the conversation.
You work on dialogue
There has been a lot of work recently using the Ubuntu dataset from Lowe et al., (2015), which was produced by heuristically disentangling conversations from the same IRC channel we use. Their work opened up a fantastic research opportunity by providing 930,000 conversations for training and evaluating dialogue systems. However, they were unable to evaluate the quality of their conversations because they had no annotated data.
Using our data, we found that only 20% of their conversations are a true prefix of a conversation (since their next utterance classification task cuts the conversation off part-way, being a true prefix is all that matters). Many conversations are missing messages, and some have extra messages from other conversations. Unsurprisingly, our trained model does better, producing conversations that are a true prefix 81% of the time. We also noticed that their heuristic was incorrectly linking messages far apart in time. This is not tested by our evaluation set, so we constructed this figure, which shows the problem is quite common:
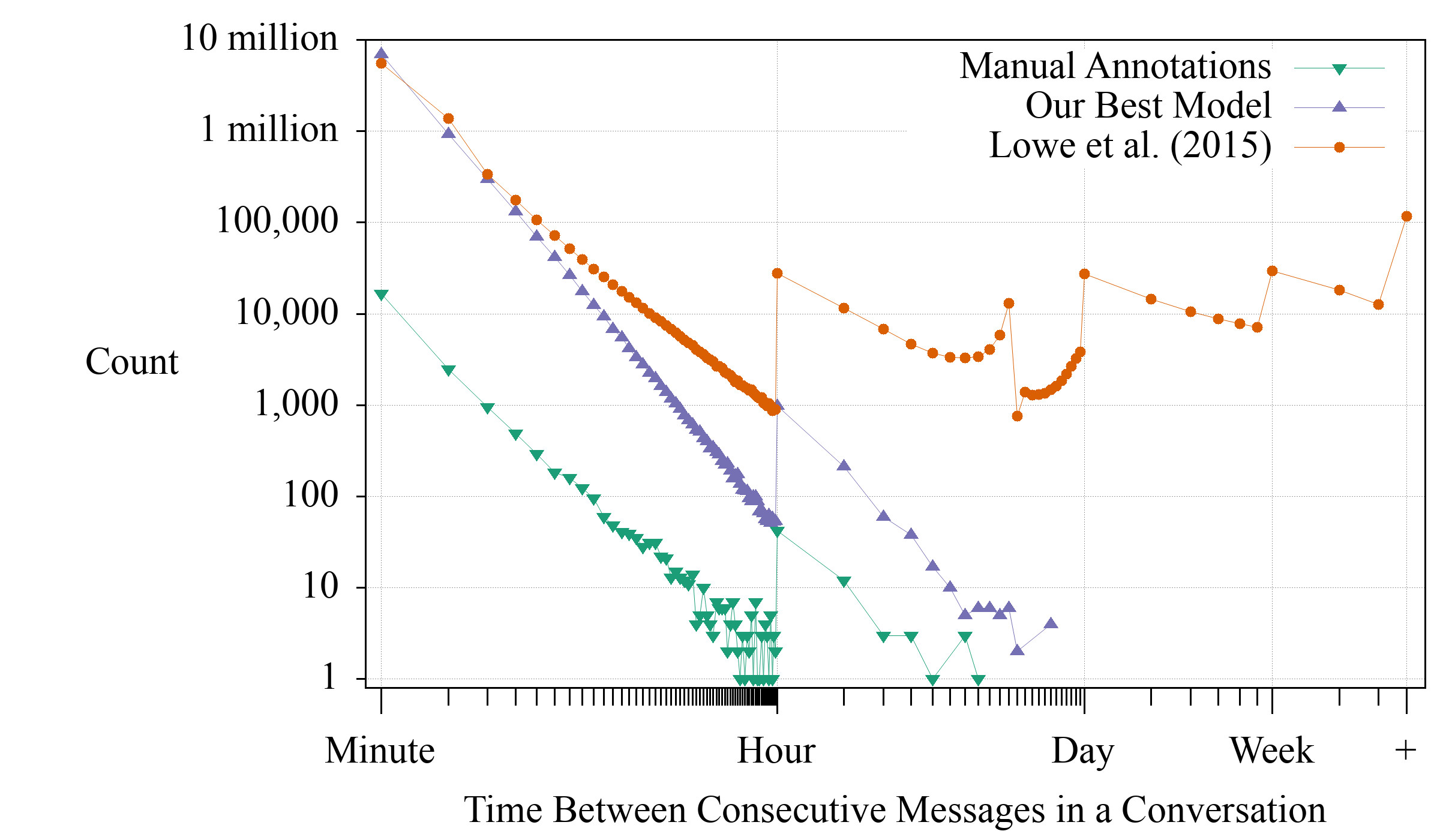
The purple results are based on the output of our model over the entire Ubuntu IRC logs. That output is the basis of DSTC 8 Track 2. Once the competition finishes (October 20th, 2019) we will release all of the conversations.
You am interested in studying online communities
This is not my area of expertise, but our data and models could enable the exploration of interesting questions. For example:
- What is the structure of the community? By looking at who asks for help and who responds we could see patterns of behaviour.
- How does a community evolve over time? This data spans 15 years, during which there were many Ubuntu releases, Stackoverflow was created, other Ubuntu forums were created, etc. It seems likely that those events and more would be reflected in the data.
It would be interesting to apply the model to other communities, but that would require additional in-domain data to get good results. We have no plans to collect additional data at this stage, and for other channels there are copyright questions that might be difficult to resolve (the Ubuntu channels have an open access license).
You mainly care about neural network architectures
We experimented with a bunch of ideas that didn’t improve performance, so our final model is very simple (a feedforward network with features representing the logs and sentences represented by averaging and max-pooling GloVe embeddings). Maybe that means there is an opportunity for you to improve on our results with a fancy model? One of our motivations for making such a large new resource was to make it possible to train sophisticated models.
Acknowledgments
This project has been going since I started at Michigan as a postdoc funded by a grant from IBM. The final paper is the result of collaboration with a large group of people from Michigan and IBM. Thank you!
Citation
@InProceedings{acl19disentangle,
author = {Kummerfeld, Jonathan K. and Gouravajhala, Sai R. and Peper, Joseph and Athreya, Vignesh and Gunasekara, Chulaka and Ganhotra, Jatin and Patel, Siva Sankalp and Polymenakos, Lazaros and Lasecki, Walter S.},
title = {A Large-Scale Corpus for Conversation Disentanglement},
title: = {A Large-Scale Corpus for Conversation Disentanglement},
booktitle = {Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
location = {Florence, Italy},
month = {July},
year = {2019},
url = {https://github.com/jkkummerfeld/irc-disentanglement/raw/master/acl19irc.pdf},
arxiv = {https://arxiv.org/abs/1810.11118},
software = {https://jkk.name/irc-disentanglement},
data = {https://jkk.name/irc-disentanglement},
}