Language Models
Model Types
Transformers
The Transformer is the core of the most successful language models. I wrote a blog post about the original paper, including this figure, which captures the network structure with a few simplifications:
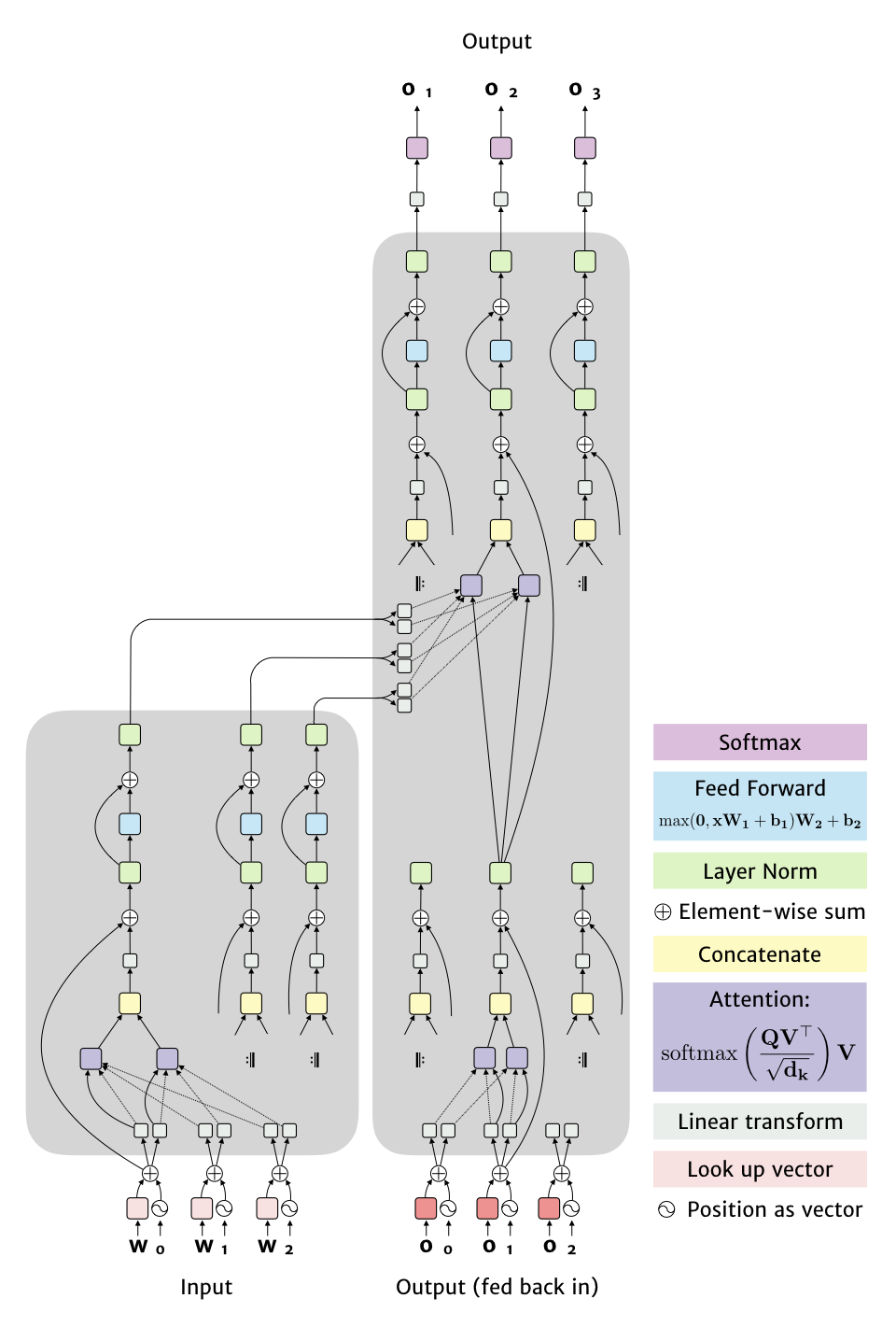
There are a few ideas being brought together here:
- Positional encoding, which is a vector of the same length as the word representation, but that depends only on the position in the input. The original paper used \(f(pos, dim) = sin(pos / 10000^{2 dim / d_w})\) for even dimensions and the cosine equivalent for odd dimensions (where \(d_w\) is the number of dimensions).
- Multi-head attention, where rather than running attention once on the full vector, multiple linear transforms are applied to get smaller vectors.
- Scaled dot product attention, the equation is shown in the figure, the key new idea is to rescale by the square root of the dimensionality so that larger vectors don’t produce excessively sharp distributions after the softmax is applied. The more general form of this described in the paper has keys (\(K\)), queries (\(Q\)) and values (\(V\)), but the network uses the same vector for the key and value. I show the query with a solid line and the values/keys with dotted lines. The matrix \(V\) is formed by using the \(v\) vectors as rows, while \(Q\) is formed by duplicating \(q\) in every row. Note, on the left hand side attention is over all input words, while on the right it is only over the words produced so far (ie. content to the left).
- Layer normalisation, a way to rescale weights to keep vector outputs in a nice range, from Ba, Kiros and Hinton (ArXiv 2016).
- Other details, (1) When the outputs are words, the vectors used to initially represent each input word are also used to represent the outputs and in the final linear transformation (though with some rescaling). (2) They use a formula I haven’t seen before to adjust the learning rate during training, (3) dropout in several places and label smoothing are used for regularization.
Simplifications in the figure:
- For multi-head attention I only show two transforms, while in practise they used 8.
- The shaded regions are duplicated 6 times to create a stack, with the output of one region acting as the input to the next copy of it. The links from left to right are always from the top of the input stack.
- The musical repeat signs indicate that the structure is essentially the same. On the output side this isn’t quite true since the attention boxes only take inputs to their left (since output to the right doesn’t exist when they are being calculated).
Since the original model, a range of variations have been explored. The PaLM paper (ArXiv, 2022) provides a nice breakdown of variations that enabled training a massive model (Section 2).
Recurrent models
Recurrent models continue to show strong performance on benchmarks like enwiki-8:
Mixture of Experts
Not it’s own type, but really a variation on other types: have a mechanism for only using part of the weights in the model at inference, depending on the content of the input. For example, GLaM uses a transformer with a set of matrices for feedforward layers, of which two are chosen for each token of input. The key advantage of this is that it can increase the number of model parameters (and so hopefully take advantage of more data) without increasing the cost of inference.
Learning at Evaluation Time
Dynamic Evaluation Krause et al. (ICML 2018) update language model parameters during inference. When a new word in the sequence is seen, the model is updated. This boosts performance, probably because it makes related words more likely. Yoshida and Gimpel (EMNLP Findings, 2021) introduced a variant, HSO, which updates the hidden states rather than the model parameters. This idea is particularly helpful with huge LMs. Again, there is an improvement in performance (small for in-domain language modelling, larger out of domain, and small for downstream tasks).
Prompt Tuning
Clear introduction and extensive literature review by Liu et al. (arXiv 2021), with updates at http://pretrain.nlpedia.ai/. The general idea is to build a system for a task by running the data through a language model with some pre-processing and post-processing. For example, for predicting movie review scores, take some text and add “This is [blank]”, then see what the model predicts for the blank word. More generally, the pre- and post-processing can be learned functions. For example, Lester et al. (EMNLP 2021) add vectors to the input that are trained using labeled data. For all but the largest LMs, this requires prompts of 20 vectors or more, initialised from class labels or vocabulary, with the LM tuned/post-trained for next word prediction (since in their case it was a model that only saw corrupted input).
This idea can also be used in a semi-supervised setup, where prompt-based models are used to label data (Schick and Hinrich Schutze, EACL 2021).
While some examples of prompts feel intuitive, that doesn’t mean they all are or that the models are working for the reason we expect. This was probed by Webson and Pavlick (arXiv 2021), who evaluated a wide set of explicit prompts for a task (ie., where the prompt is natural language rather than a trained vector). They found that using what a person would deem a good prompt is no better than irrelevant prompts, null prompts, and one misleading prompt (“Does the paragraph start with ’the’?). For answer types (yes-no vs. dog-cat), a more intuitive answer does appear to do better, but it is unclear why yes-no is better than true-false (for example). Similarly, Cao, et. al. (ACL 2021) studied the ability to treat an LM as a database, with prompts retrieving information. They showed that prior success was mainly due to biases in the evaluation data, with spurious answers occuring (e.g., always predicting London as a place of birth), and higher performing prompts simply fitting the answer distribution of the evaluation data better.
- Finetuning on instructions https://arxiv.org/pdf/2109.01652.pdf
Speeding up
One way to save computation is to only run some of the layers in a stack. CALM predicts when early stopping is possible without changing the output, leading to similar results in about half the time.
Training data
Training models on higher quality data can produce strong results even when there is relatively little data. This has been shown for code (Gunasekar et al., arXiv 2023) and stories (Eldan and Li, arXiv 2023), where in both cases a large model is used to either generate data or filter existing data to create a small high-qiality dataset for training a small model.
Training objective
- GOLD, https://openreview.net/pdf?id=RovX-uQ1Hua
- Tempering, https://aclanthology.org/2021.mtsummit-research.10/, Note that AlphaCode experiments found a lower temperature was best
Guiding Inference
Chung et al. (CHI 2022) built a system in which users can specify how the fortune of a protagonist in a generated story should vary over the story (like Kurt Vonnegut’s famous drawings).
Tokenisation
Most LMs today use a word-piece tokenisation, where rare or unseen words are broken into pieces. For constructing these vocabularies, there are several approaches:
- BPE https://aclanthology.org/P16-1162.pdf, which can be implemented more efficiently, in O(N log M) time where N is the sequence length and M is the number of merges (Zouhar, et al. (ACL 2023)
- Unigram tokenizer
- WordPiece https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/37842.pdf
- Unigram LM https://aclanthology.org/P18-1007/
Compared in https://aclanthology.org/2020.findings-emnlp.414.pdf
Library: SentencePiece https://github.com/google/sentencepiece, https://aclanthology.org/D18-2012/
For inference, Song et al. (EMNLP 2021) improved efficiency by forming a special trie that encodes all the known words and pieces, with extra edges that show what to produce when a match fails.
Analysis
What are these LMs [not] learning?
Syntactic constraints are one way to probe these models, e.g., do they correctly model number agreement for noun-verb pairs? Wei et al. (EMNLP 2021) showed the answer to that question is yes, though they have difficulty with rarer words (interestingly, a frequency of ~100 seems to be a convergence point, similar to the point at which static word embeddings are stable in my work with Laura Burdick). BERT also has trouble when one form is far more common than another.
For models made available only via APIs, one challenge is that newer versions may not behave the same as older ones. Chen et al. (arXiv 2023) show this for GPT 3.5 and GPT 4, with a range of changes in just three months. Some changes are consistent (e.g., decrease in verbosity for GPT 4), but most vary across tasks, including both higher and lower scores.
Use in Evaluation
For text generation tasks, evaluation is difficult. Zhang et al. (ICLR 2020) proposed BERTscore, which uses BERT to calculate similarity between tokens in output and a reference, followed by greedy matching and averaging to get an overall score. Yuan et al. (NeurIPS 2021) switch to BART and note that for an application like machine translation you can also make a comparison with the source text, and the comparison can be done in one direction or another between reference and generated text. It is similar in performance to BERTscore, but they also explore finetuning and prompting, which improve performance. Kasai et al. (arXiv 2021) propose forming an ensemble of metrics, learning a combined metric that correlates best with buman evaluations. In their model, leaderboards accept both new models and new metrics, updating the results in the process.