This directory contains a simple baseline approach for mapping text to SQL:
- Identify an SQL template for this question
- Choose words in the question to fill slots in the template
The model uses a bi-directional LSTM to predict a label for each word, indicating what type of slot it fills. The final hidden states of the LSTM are used to predict the template. There is no enforcement of agreement between the template and the slots. Visually, for the sentence “Flights from Denver to Boston” it looks like this:
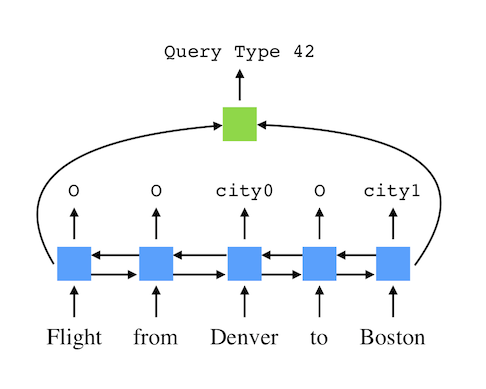
This approach is motivated by our observation of overlap between train and test in question-based data splits. It will completely fail on query-based data splits, but does surprisingly well on question-based splits, making it a nice baseline.
If you use this code, please cite our ACL paper:
@InProceedings{data-sql-advising,
author = {Catherine Finegan-Dollak, Jonathan K. Kummerfeld, Li Zhang, Karthik Ramanathan, Sesh Sadasivam, Rui Zhang, and Dragomir Radev},
title = {Improving Text-to-SQL Evaluation Methodology},
booktitle = {Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
month = {July},
year = {2018},
address = {Melbourne, Victoria, Australia},
pages = {351--360},
url = {http://aclweb.org/anthology/P18-1033},
}
Note on evaluation bugs
After publication we were made aware (via GitHub issues) of two bugs in the baseline model. First, the template generation did not correctly consider variables that are implicitly defined by the text (the intention was that multiple templates would be created for such cases). This meant that the evaluation, which only checked if the right template was chosen and the right tags were assigned, was incorrect. We fixed the bug and changed the evaluation to compare the filled in query. Second, the splits were not correctly determined for the smaller datasets
The table below shows the old and new results, with substantial shifts (5+) in bold with a star. None of the non-oracle results shifted substantially. There are some large drops for the oracle entities setting (ATIS and Scholar), but the results do not change the findings of the paper. The reason some values improved is that when filling in the query with slots tags that are inconsistent with the chosen template are ignored (and so cases that were previously wrong are now right).
| System | Advising | ATIS | GeoQuery | Scholar | Restaurants | Academic | IMDB | Yelp |
|---|---|---|---|---|---|---|---|---|
| Old Baseline | 80 | 46 | 57 | 52 | 95 | 0 | 0 | 1 |
| New Baseline | 83 | 45 | 57 | 54 | 93 | 0 | 2 | 2 |
| Old Oracle Entities | 89 | 56 | 56 | 66 | 95 | 0 | 7 | 8 |
| New Oracle Entities | 87 | *49 | 59 | *59 | 93 | 0 | *2 | 6 |
| Old Oracle All | 100 | 69 | 78 | 84 | 100 | 11 | 47 | 25 |
| New Oracle All | 100 | 66 | 78 | 82 | 100 | 11 | 47 | 25 |
Requirements
- Python 3
- Dynet
Running
To see all options, run:
./text2sql-template-baseline.py --help
To run with all the defaults, simply do:
./text2sql-template-baseline.py <data_file>
For the smaller datasets (Academic, Restaurants, IMDB, Yelp), cross-validation is used rather than a simple train-dev-test split.
To handle that, use the --split flag, with an argument indicating the split number, for example:
./text2sql-template-baseline.py data/restaurants.json --split 0
Parameters used for paper results
The parameters were varied slightly for each dataset (any not listed here were set to the default). The following flags were set for evaluation on all datasets:
--eval-freq 1000000 --log-freq 1000000 --max-bad-iters -1 --do-test-eval
| Dataset | Parameter | Value |
|---|---|---|
| Advising | max-iters | 40 |
| Geography | dim-word | 64 |
| ” | dim-hidden-lstm | 128 |
| ” | dim-hidden-template | 32 |
| ” | max-iters | 31 |
| Scholar | lstm-layers | 1 |
| ” | max-iters | 17 |
| ATIS | learning-rate | 0.05 |
| ” | max-iters | 22 |
| Academic, IMDB, Restaurants, Yelp | dim-word | 64 |
| ” | dim-hidden-template | 32 |
| ” | train-noise | 0.0 |
| ” | lstm-layers | 1 |
| ” | max-iters | 3 |
For example, this will run all of the experiments (assuming you are in this folder, have DyNet installed, and have four cores):
#!/bin/bash
for i in `seq 1 8` ; do
to_wait=""
data="scholar"
./text2sql-template-baseline.py ../../data/${data}.json --eval-freq 1000000 --log-freq 1000000 --max-bad-iters -1 --do-test-eval --max-iters 17 --lstm-layers 1 >out.${data}.${i}.txt 2>err.${data}.${i}.txt &
to_wait="${to_wait} $!"
data="geography"
./text2sql-template-baseline.py ../../data/${data}.json --eval-freq 1000000 --log-freq 1000000 --max-bad-iters -1 --do-test-eval --max-iters 31 --dim-word 64 --dim-hidden-lstm 128 --dim-hidden-template 32 >out.${data}.${i}.txt 2>err.${data}.${i}.txt &
to_wait="${to_wait} $!"
data="advising"
./text2sql-template-baseline.py ../../data/${data}.json --eval-freq 1000000 --log-freq 1000000 --max-bad-iters -1 --do-test-eval --max-iters 40 >out.${data}.${i}.txt 2>err.${data}.${i}.txt &
to_wait="${to_wait} $!"
data="atis"
./text2sql-template-baseline.py ../../data/${data}.json --eval-freq 1000000 --log-freq 1000000 --max-bad-iters -1 --do-test-eval --max-iters 22 --learning-rate 0.05 >out.${data}.${i}.txt 2>err.${data}.${i}.txt &
to_wait="${to_wait} $!"
wait $to_wait
done
for data in academic yelp imdb restaurants ; do
for i in `seq 0 9` ; do
./text2sql-template-baseline.py ../../data/${data}.json --split $i --dim-word 64 --dim-hidden-template 32 --train-noise 0.0 --lstm-layers 1 --max-iters 3 --eval-freq 1000000 --log-freq 1000000 --max-bad-iters -1 --do-test-eval >out.${data}.split${i}.txt 2>err.${data}.split${i}.txt
done
done
License
This code is a modified version of the example tagger code from the DyNet repository. It is available under an Apache 2 license.