This software classifies errors in the output of coreference resolution systems. For a full description of the method, and discussion of results when applied to the systems from the 2011 CoNLL Shared Task, see:
Error-Driven Analysis of Challenges in Coreference Resolution Jonathan K. Kummerfeld and Dan Klein, EMNLP 2013
To use the system, download it one of these ways, and run classify_coreference_errors.py as shown below:
- Download .zip
- Download .tar.gz
git clone https://github.com/jkkummerfeld/berkeley-coreference-analyser.git
If you use my code in your own work, please cite the paper:
@InProceedings{Kummerfeld-Klein:2013:EMNLP,
author = {Jonathan K. Kummerfeld and Dan Klein},
title = {Error-Driven Analysis of Challenges in Coreference Resolution},
booktitle = {Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing},
address = {Seattle, Washington, USA},
month = {October},
year = {2013},
pages = {265--277},
url = {http://www.aclweb.org/anthology/D13-1027},
software = {https://github.com/jkkummerfeld/berkeley-coreference-analyser},
}
Example of system output (groupings indicate system clusters, colours indicate gold clusters):
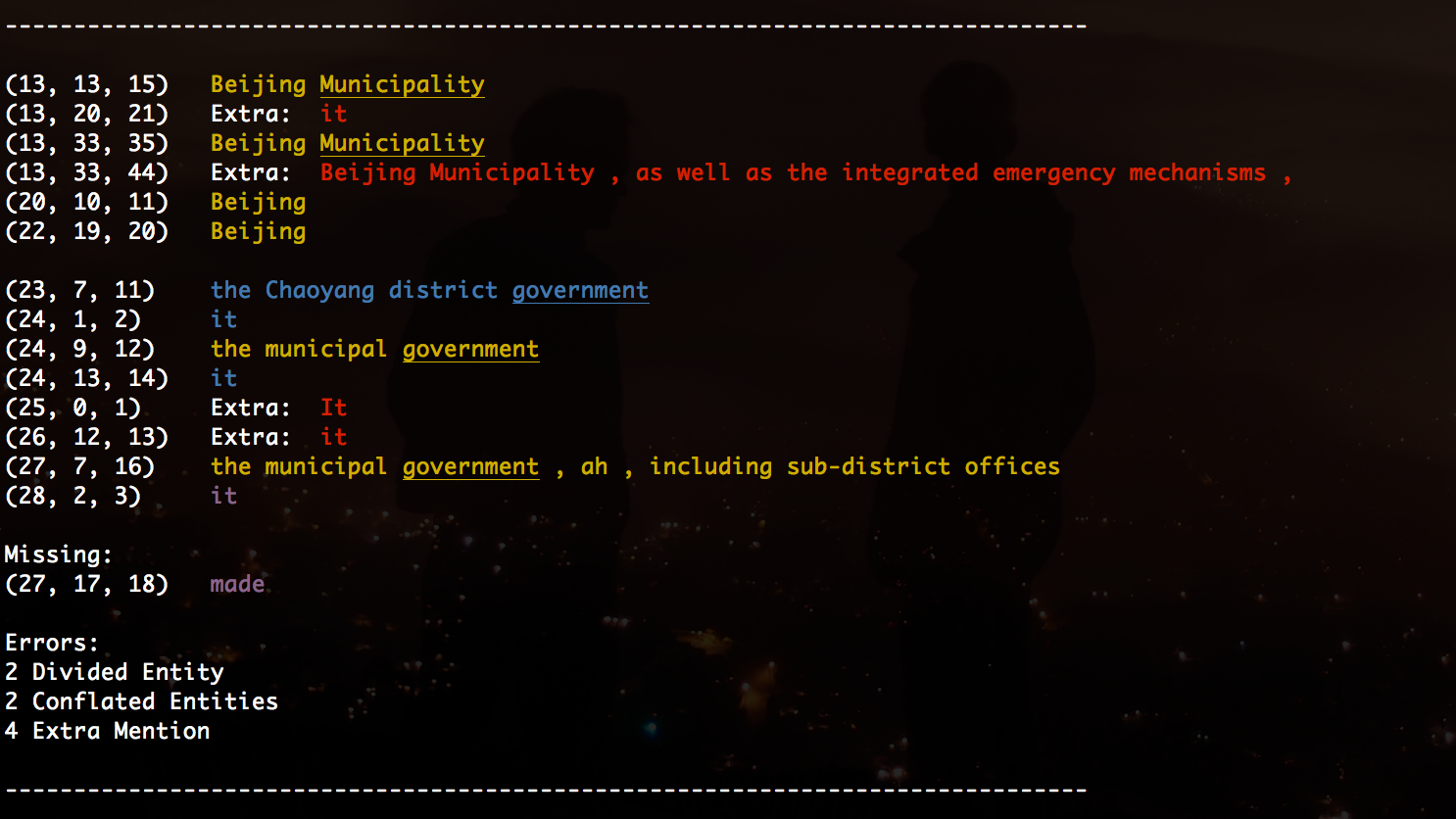
Running the System
There are three main programs:
- classify_coreference_errors.py, Classify errors in system output, using the CoNLL output format
- print_errors.py, Print system output in several ways, to illustrate the errors
- coreference_format_conversion.py, Convert the output of several systems to the CoNLL format
Running each with no arguments will provide help information. Also see the sample folders for example runs. These were generated as follows:
./classify_coreference_errors.py data/classified/stanford data/gold/ data/homogenised/stanford.homogenised.out T
./print_errors.py data/pretty_printed/stanford data/gold/ data/homogenised/stanford.homogenised.out F
./coreference_format_conversion.py data/homogenised/stanford.homogenised stanford_xml data/stanford_xml_out/ data/gold/
For the error analysis runs the files produced are:
- stanford.summary - Counts of errors, and counts of the raw operations involved.
- stanford.classified - A simple view of the errors.
- stanford.classified.detailed - Same as the previous file, but with extra output describing properties of each error.
- stanford.classified.properties - Every error gets a single line, with a list of properties (see the top of the file for an explanation of properties).
The rest of the files are output in the CoNLL format that has some of the errors corrected, for use in measuring the impact of each error type:
- stanford.gold
- stanford.system
- stanford.corrected.none
- stanford.corrected.span_errors
- stanford.corrected.confused_entities
- stanford.corrected.extra_mention
- stanford.corrected.extra_entity
- stanford.corrected.divided
- stanford.corrected.missing_mention
- stanford.corrected.missing_entity
These are similar to the above files, but with errors progressively corrected, so by the final file there are no errors left.
- stanford.corrected.extra_mention_prog
- stanford.corrected.extra_entity_prog
- stanford.corrected.divided_prog
- stanford.corrected.missing_mention_prog
- stanford.corrected.missing_entity_prog
Running the commands with an invalid number of arguments will give you the following execution information:
./classify_coreference_errors.py <output_prefix> <gold_dir> <test_file> [remove singletons? T | F (default is True)]
./print_errors.py <prefix> <gold_dir> <test> [resolve span errors first? T | F]
./coreference_format_conversion.py <prefix> <[cherrypicker,ims,bart,conll,stanford_xml,stanford,uiuc,reconcile]> <dir | file> <gold dir>
Questions and Answers
Q: What about languages other than English?
A: In principle the code is fairly language agnostic, the main thing that would need to be altered is the head finder. I do not plan to add support for other languages in the near future, but am happy to accept pull requests!